配置开始
首先,确保虚拟机完成了网卡、主机名等配置,安装了jdk以及hadoop。
| ip地址 | 主机名 | 节点 |
|---|---|---|
| 172.20.10.10 | hadoop1 | 主节点 |
| 172.20.10.9 | hadoop2 | 子节点 |
下面的操作都是在主节点的操作:

然后,输入指令cd /etc/hadoop
(1)修改core-site.xml文件
<configuration>
<property>
<!-- 指定namenode在hadoop1虚拟机上-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<!--块大小-->
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<!--hadoop临时目录-->
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
(2)修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name><!--每个子节点路径不一样就行-->
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<!--指定Hdfs副本数量-->
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
(3)修改mapred-site.xml(复制mapred-site.xml.template,再修改文件名)
cp mapred-site.xml.template mapred-site.xml
<configuration>
<!--MR核心配置文件-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
(4)修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
</configuration>
(5)修改masters文件,需要自己创建
里面是主节点的信息
hadoop1
(6)修改slaves文件
里面是子节点
hadoop2
(7)把这些拷贝到其他节点中
scp -r hadoop hadoop2:/sw/hadoop/etc/

(8)创建目录,就是你前面配置文件中的目录

(9)赋予权限
sudo groupadd hadoop
sudo useradd -g hadoop1 hadoop -s /bin/false
sudo chown -R hadoop1:hadoop /usr/local/hadoop
将/usr/local拷贝到子节点
scp -r /usr/local/hadoop hadoop2:/usr/local

(10)配置变量,子节点
vi ~/.bashrc
在前面安装Hadoop已经配置了,所以这一步可以忽略,如果没有配置,请看前一节。

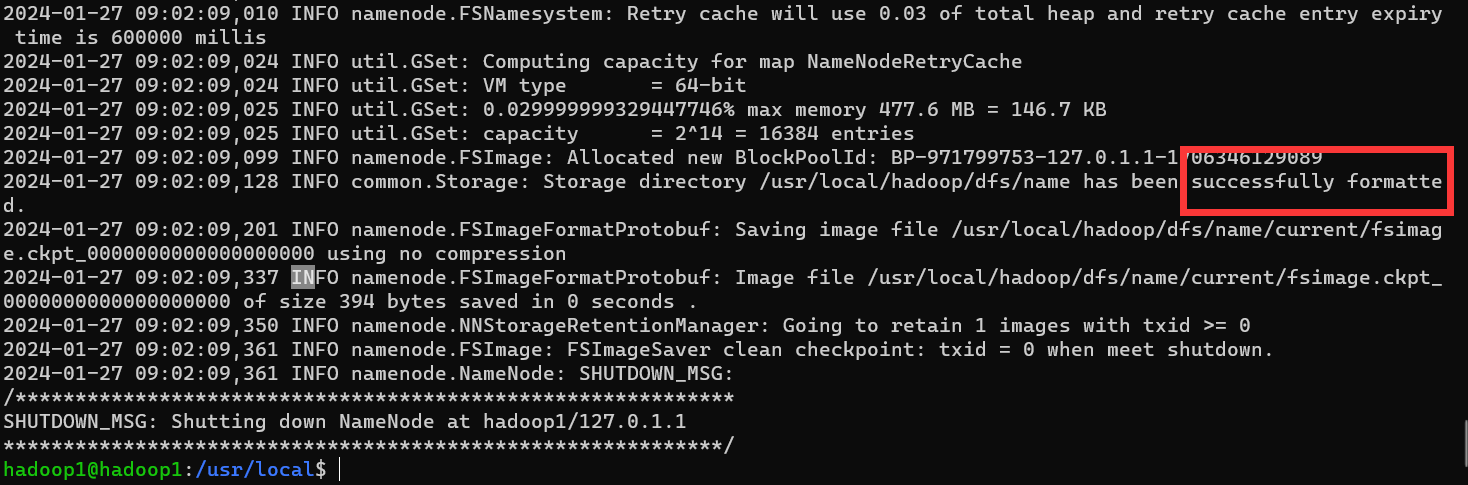
(11)格式化,主节点上
hadoop namenode -format
(12)启动集群
start-all.sh一键启动所有集群,必须相互免密登录
尽量使用下面指令
start-dfs.sh
start-yarn.sh
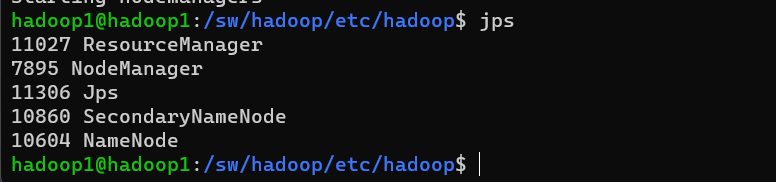
输入jps可以看节点信息
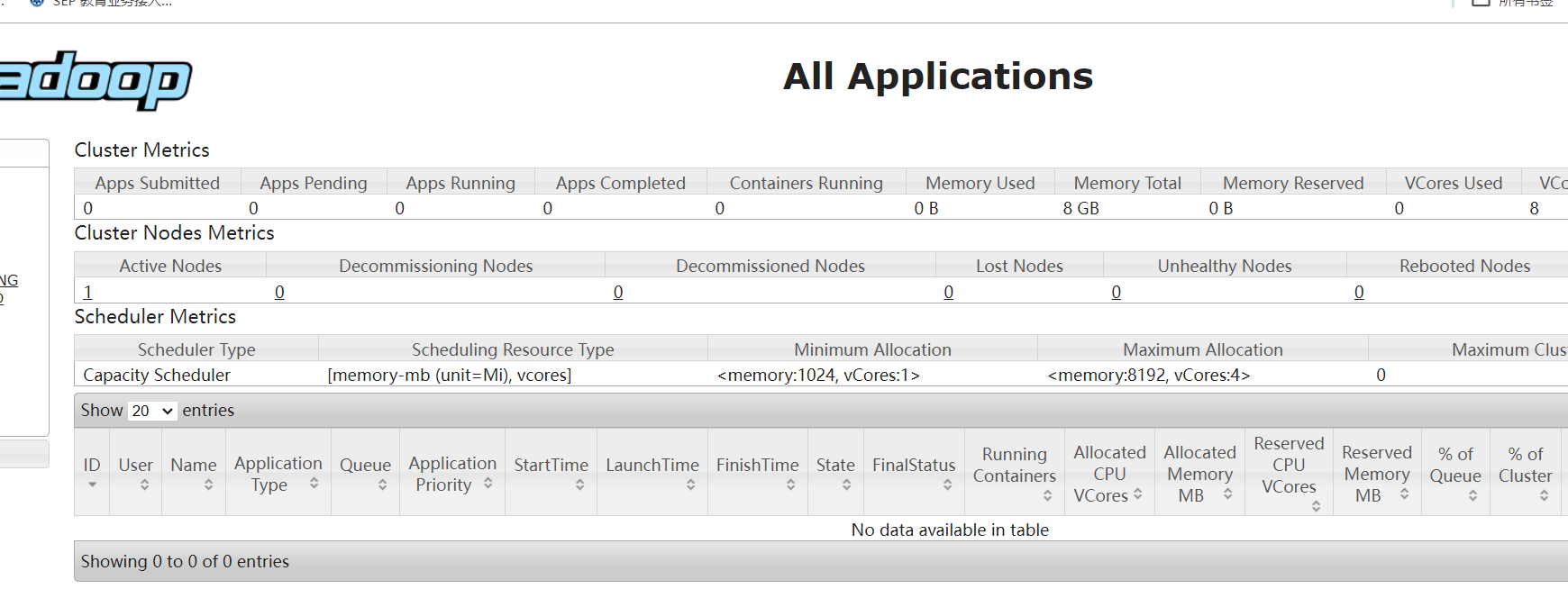
也可以windows上查看,
sudo ufw status#查看防火墙状态,如果是开启则关闭
sudo ufw disable
然后在windows输入主机ip:172.20.10.10:9870(HDFS文件系统)
172.20.10.10:8088(YARN服务)